Interruption Handling in Conversational AI: Building Resilience in Real-Time Conversations

In human conversation, interruptions are not only expected—they’re essential. Whether a speaker is clarifying a misunderstanding, correcting a misstatement, or simply interjecting with urgency, interruptions contribute to natural, dynamic interactions. For voice AI systems striving for human-like fluency, interruption handling isn’t optional—it’s a core capability.
This blog explores the technical intricacies of interruption handling in conversational AI pipelines, from voice activity detection (VAD) to audio playout control, pipeline cancellation, and context synchronization with large language models (LLMs).
🔄 What Is Interruption Handling?
Interruption handling refers to the system’s ability to recognize and appropriately respond when the user begins speaking while the AI agent is mid-response. This behavior mimics human conversational norms and is critical for real-time, voice-first interfaces such as virtual assistants, IVR bots, and in-car voice agents.
Effective interruption handling must:
- Detect interruptions accurately.
- Cancel in-flight processing cleanly.
- Stop ongoing audio playback immediately.
- Synchronize conversation context post-interruption.
Key Insight
Interruption handling is a cornerstone of human-like AI interaction. This blog breaks down the mechanics of detecting, canceling, and recovering from real-time interruptions in voice-first systems.
🧱 Pipeline Design for Interruption Support
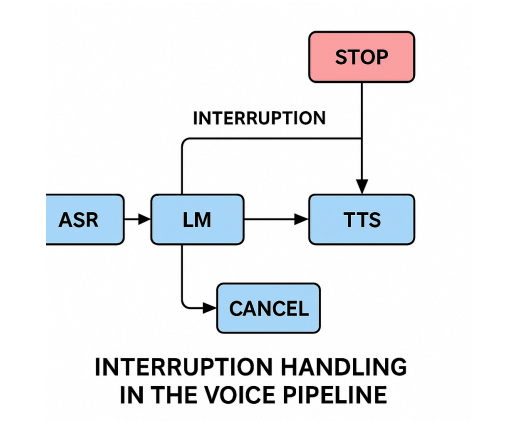
To support interruptions robustly, every component in your pipeline must be interrupt-aware and cancellable. That includes:
- ASR (Automatic Speech Recognition)
- LLM inference
- TTS (Text-to-Speech)
- Audio playout layers
Many frameworks (e.g., Deepgram, Whisper-based platforms, or Pipecat) provide APIs that support cancellation or dynamic state control. However, when you're building at a lower level, especially with raw audio streaming, you must explicitly implement:
- Audio buffer flushing
- Real-time stream control
- Preemption-safe state management
⛔ Instant Audio Playout Cancellation
Interrupt handling is only effective if the client-side audio playout stops the instant an interruption is detected. This involves:
- Monitoring for user speech during playout.
- Triggering a playout stop within a few milliseconds.
- Discarding or queuing LLM output appropriately.
In platforms using WebRTC or WebSockets for audio transport, client audio buffers must be flushed proactively. Use AudioContext.suspend() (in web apps) or native SDK-specific methods to stop playback instantly.
Core Components
- Voice Activity Detection (VAD) Understand how accurate interruption detection depends on VAD segment length, confidence thresholds, and post-VAD smoothing.
- Audio Pipeline Cancellation Learn how to implement interrupt-aware, cancellable pipelines including ASR, LLM inference, and TTS for responsive systems.
- Instant Audio Playout Control Explore techniques to stop client-side audio playback within milliseconds using buffer flushing and platform-specific controls.
- False Positive Mitigation Discover how to avoid spurious interruptions caused by transient noises, echo leakage, and background speech.
- Context Synchronization Post-Interruption Preserve conversational integrity by aligning generated responses with what the user actually heard using TTS word-level timestamps.
❗ Avoiding Spurious Interruptions
False positives are a major concern in interruption detection. These arise when the system mistakes non-speech sounds for real user intent. Some common culprits:
🔊 1. Transient Noises Classified as Speech
Sharp non-verbal sounds—keyboard clicks, coughs, or door slams—can sometimes pass VAD thresholds.
Mitigation Techniques:
- Increase VAD segment length: Require more audio before detecting a new utterance.
- Raise confidence thresholds: Filter low-certainty speech detections.
- Post-VAD smoothing: Apply exponential decay to avoid abrupt transitions in VAD state.
Trade-off: Overcorrecting may cause missed detection of short affirmations (“yes,” “okay”).
🔄 2. Echo Cancellation Failures
Even sophisticated AEC (Acoustic Echo Cancellation) systems can leak initial playout audio into the input mic—causing self-interruptions by the bot.
Countermeasures:
- Apply min-VAD segment length to dampen short-lived audio feedback.
- Use volume smoothing to suppress sharp rises.
- Implement echo-detection-aware suppression on playback start.
Implementation Roadmap
- 1Implement cancellable pipelines for ASR, LLM, and TTS components
- 2Flush audio buffers instantly on interruption using client-side APIs
- 3Tune VAD segment length and confidence thresholds to reduce noise
- 4Add echo cancellation and speaker isolation for accurate detection
- 5Use TTS timestamps to retain only heard output in conversation context
🗣 3. Background Speech
The VAD model typically cannot differentiate between the user’s voice and background human speech.
Solution:
- Integrate speaker diarization or source separation models.
- Use far-field microphone arrays or directional beamforming (if hardware allows).
- Deploy server-side speaker isolation techniques, e.g., RNNoise, DeepFilterNet, or proprietary DSP pipelines.
🧠 Context Accuracy After an Interruption
Modern LLMs generate output faster than real-time. If the AI is interrupted mid-response, you face a dilemma:
- The model may have already generated and queued words the user never heard.
If this output is blindly added to the context, it corrupts the next response by referencing a shared history that didn't actually happen.
✅ Solution: Reconstruct What Was Heard
To preserve contextual accuracy, buffer and align the TTS output with word-level timestamps. On interruption:
- Use TTS timestamps to determine which portion of the response was actually played.
- Truncate the assistant’s generated text accordingly.
- Only retain text that matches audio the user heard.
This is especially crucial when storing transcripts or generating follow-up responses.
Tools & Techniques
Amazon Polly, Google TTS, and Microsoft Azure TTS offer word-timestamp metadata.
Open-source alternatives (e.g., Coqui TTS or ESPnet) can be configured for alignment with forced alignment tools (e.g., Gentle).
Pipecat, an open-source voice AI stack, handles this process automatically by synchronizing TTS output with actual playback.
⚙ Practical Implementation Checklist
| Task | Description |
|---|---|
| 🔄 Cancel pipeline | Enable cancellation of STT, LLM, and TTS in your architecture. |
| ⏹ Stop audio instantly | Use client-side methods to flush playback buffers. |
| 🧠 Sync context | Align user-perceived audio with LLM context using timestamps. |
| 🎯 Tune VAD | Optimize segment length and confidence thresholds. |
| 🧽 Filter noise | Add speaker isolation, echo suppression, and smoothing layers. |
| 🧪 Test rigorously | Validate with real users in noisy and edge-case scenarios. |
🧭 Conclusion
Interruption handling is not a feature—it's a requirement for fluid, responsive conversational AI. By designing cancellable pipelines, applying intelligent VAD tuning, and maintaining accurate post-interruption context, developers can craft systems that feel truly conversational.
As voice interfaces proliferate across industries—from healthcare to automotive to finance—the ability to handle interruptions gracefully becomes a key differentiator between a frustrating experience and a delightful one.
If you’re building or scaling a voice-first product, make interruption handling a first-class design goal, not an afterthought.
Ready to Transform Your Customer Service?
Discover how Zoice's conversation intelligence platform can help you enhance CLV and build lasting customer loyalty.