Latency in Conversational AI: Why It Matters (and How to Tackle It)
Abhishek Sharma
AI & Conversational Systems Engineer

In human conversation, silence over half a second feels awkward. In voice AI, even 300 milliseconds of latency can disrupt flow. Latency isn’t a backend metric — it’s user experience itself. In this post, we unpack what truly drives voice AI delay and how to tackle it for snappy, human-like responsiveness.
Key Insight
Voice AI must operate under tight latency constraints to feel natural. Learn how to measure and optimize latency across the voice-to-voice pipeline — from STT to LLMs to TTS.
On this page
Why Latency Matters
Humans typically respond within 300–500 ms. Delays beyond 120 ms are noticeable, and those over 500 ms feel unnatural (Telnyx). Latency isn’t a minor detail — it’s the difference between fluent and frustrating voice interactions.
Many AI platforms tout inference speeds. But real latency includes:
- Speech-to-Text (STT) + endpoint detection
- Audio encoding/decoding
- Network transport
- LLM inference + token streaming
- Text-to-Speech (TTS) playback
True latency = voice-to-voice: from end of user speech to first audio byte of response.
Core Components
The only reliable metric for user-perceived latency is the time between end-of-user-speech and start-of-agent-audio — not just model inference time.
Voice input pipelines involve mic capture, network transport, STT, model inference, TTS, and final playback — each adding milliseconds of delay.
Models like GPT‑4o, Gemini Flash, and LLaMA‑Omni can deliver fast responses (≤ 500 ms TTFT), critical for smooth conversational UX.
Parallel LLM calls, co-located inference clusters, STT endpoint tuning, and speculative decoding all help shrink latency further.
Monitoring tail latencies, scaling dynamically under load, and making infrastructure trade-offs are key to sustainable, real-time performance.
Anatomy of Voice-to-Voice Latency
Here’s a breakdown of the stages contributing to end-to-end delay:
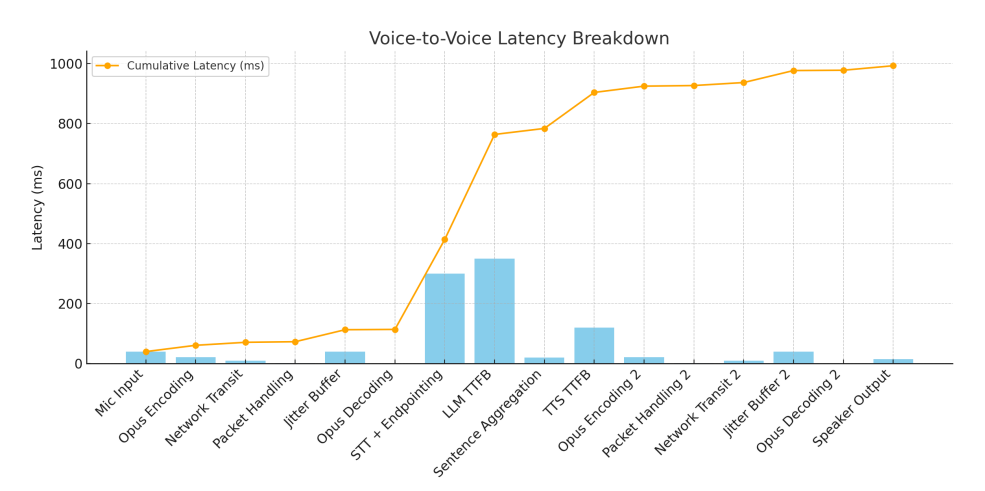
| Stage | Time (ms) | Details |
|---|---|---|
| Mic input | ~40 | ADC + OS buffering |
| Opus encoding | 21–30 | Audio compression |
| Network transit | 10–50 | Varies by region |
| STT + endpointing | 200–300 | Speech recognition + pause detection |
| LLM time-to-first-token | 100–460 | Inference start latency |
| TTS (TTFB) | 80–120 | Time to start streaming speech |
| Jitter buffering + playback | 50+ | Final audio delivery |
Even in optimized systems, total latency hovers between 800–1,000 ms. However, cutting-edge pipelines (GPU cluster hosted) can bring this down to 500–600 ms.
Implementation Roadmap
- 1Record real conversations and measure end-of-speech to first audio byte
- 2Optimize STT endpointing for minimal delay (target ~100ms)
- 3Use low-TTFT LLMs (≤ 500ms) like GPT‑4o, Gemini Flash, LLaMA‑Omni
- 4Implement parallel model querying and early TTS synthesis
- 5Co-locate services and deploy inference at the edge
- 6Continuously monitor tail latency and scale based on load
Optimization Strategies
- Trim STT endpointing: Reduce punctuation delays from 1.5s to ~100ms (AssemblyAI).
- Co-locate services: Run STT, LLM, and TTS in the same region or GPU cluster.
- Use edge/CDN deployments: Serve users close to where they are.
- Parallel LLM calls: Query multiple models and return the fastest.
- Speculative decoding: Begin generating response while STT is still transcribing.
- Use lightweight starter models: Trigger fast TTS with smaller LLMs while deeper models process longer input.
Which LLMs Are Fast Enough?
Based on May 2025 TTFT benchmarks:
- GPT‑4o: 460 ms median / 580 ms P95 ✅
- Gemini Flash: 380 ms / 450 ms ✅
- LLaMA 4 Maverick (Groq): 290 ms / 360 ms ✅
- Claude Sonnet 3.7: 1,410 ms / 2,140 ms ❌
Rule of thumb: TTFT ≤ 500 ms is required for real-time conversational quality.
Business & Technical Implications
User Engagement: Latency affects retention — even a 300 ms hiccup harms flow. Half-second pauses break immersion.
Scalability: A 1 s demo latency can double under real-world load. Monitor tail latency and scale proactively.
Cost Trade-offs: Techniques like parallel LLM calls cost more, but pay off in user satisfaction.
Infrastructure: Edge deployment and GPU clustering increase OPEX, but are essential for real-time UX.
Looking Ahead
Speculative models: Techniques like PredGen halve latency by predicting LLM output mid-speech.
Open source innovations: Projects like LLaMA‑Omni are hitting 226 ms full loop performance.
In time, sub-500 ms voice-to-voice latency may become table stakes. For now, reaching it requires precise engineering and architectural choices.
Conclusion
Latency is the invisible thread binding a voice conversation together. Optimize it, and your AI sounds intelligent and fluid. Ignore it, and the illusion of human-like interaction vanishes. Build with latency at the forefront — your users will notice.
🔍 Final Recommendations:
- Measure voice-to-voice latency, not just server metrics
- Target 500–800 ms end-to-end latency
- Use fast LLMs (≤ 500 ms TTFT)
- Optimize pipeline structure and endpoint behavior
- Watch for tail latency — that’s where user trust breaks
Latency isn’t just a metric — it’s the heartbeat of voice AI. Prioritize it accordingly.
Links are rel="nofollow" as per best practice.
Written by
Abhishek Sharma
AI & Conversational Systems Engineer
Abhishek Sharma is an AI engineer at Zoice specialising in the technical foundations of conversational AI — real-time audio pipelines, LLM orchestration, voice activity detection, multi-agent systems, and production voice AI for Indian languages. He covers the engineering decisions behind how Zoice's voice, chat, and WhatsApp agents are built and scaled.
Keep reading
All articles
Connect Plivo to Zoice: A Step-by-Step Guide to Putting an AI Agent on Your Phone Number
June 14, 2026 · 7 min read
Read more
WhatsApp Business API Without a BSP: What Skipping the Middleman Actually Means
June 12, 2026 · 6 min read
Read more
BYOC for Voice AI: Wiring Your Own SIP Trunks into AI Agents (and Why Telephony Margins Matter)
June 10, 2026 · 7 min read
Read moreReady to put an AI agent to work?
Deploy voice, WhatsApp, and chat agents across Indian languages — grounded in your knowledge and measured on every call.